How to Monitor Website Uptime
If there's one thing I've learned during my time in the software industry, its that monitoring your software is important. If you want your website to be taken seriously, you don't want it to all of a sudden be down without you knowing for hours, or even days. This is where the topics of monitoring, alerting and overall software observability come in.
In this blog post, I'll be running through some industry standard monitoring tools and how to deploy and configure them to monitor any website's uptime. This might also be the start of a series of blog posts expanding on Kubernetes observability infrastructure, but we'll see.
The tools we'll be using are the following:
- Prometheus
- Grafana
- The Prometheus Black box Exporter
I'll run through those in a bit of detail before we get started.
Prometheus is a metrics aggregator. Its configured with a series of endpoints that it can scrape for metrics in a format that it understands, and it stores them in a time series database.
Grafana is a metrics visualization tool. This is where you take Prometheus's metrics, and build pretty graphs and charts that explain the data.
Finally, the Prometheus Black box Exporter is one of many Prometheus exporters. An exporter in Prometheus terms is essentially an app that allows the user to easily export metrics in a way Prometheus understands. The Black box exporter is an app that knows how to essentially ping endpoints and collect metrics based on what came back, e.g. did the endpoint return a 200 response code? How long did it take to respond? Is its SSL configuration valid? In a similar vein, there are other Prometheus exporters that do other things like collecting basic metrics (Node Exporter), collect JMX metrics for Java applications (JMX Exporter), there's even some community exporters that can collect metrics for certain kinds of smart home devices!
Now, to start the process of getting our website monitored, we need to first deploy our K8s infrastructure. I'll be using Helmfile to conduct this deployment, which you can read more about in my previous blog post about that subject. This is what my helmfile.yaml looks like:
1repositories:
2- name: grafana
3 url: https://grafana.github.io/helm-charts
4- name: prometheus-community
5 url: https://prometheus-community.github.io/helm-charts
6
7releases:
8 - name: grafana
9 namespace: observability
10 chart: grafana/grafana
11 values:
12 - ./grafana/values.yaml
13
14 - name: prometheus-operator
15 namespace: observability
16 chart: prometheus-community/kube-prometheus-stack
17 values:
18 - ./prometheus-operator/values.yaml
19
20 - name: prometheus-blackbox-exporter
21 namespace: observability
22 chart: prometheus-community/prometheus-blackbox-exporter
23 values:
24 - ./prometheus-blackbox-exporter/values.yaml
25 needs:
26 - observability/prometheus-operator
And here are the corresponding values.yaml files for each Helm release:
Grafana:
1rbac:
2 create: false
3serviceAccount:
4 create: false
5
6replicas: 1
7
8image:
9 repository: grafana/grafana
10 tag: 8.3.4
11 sha: ""
12 pullPolicy: IfNotPresent
13
14
15service:
16 enabled: true
17 type: NodePort
18 port: 80
19 nodePort: 30001
20 targetPort: 3000
21 portName: service
22
23resources:
24 limits:
25 cpu: 200m
26 memory: 256Mi
27 requests:
28 cpu: 100m
29 memory: 128Mi
30
31
32persistence:
33 type: statefulset
34 enabled: true
35 size: 10Gi
36
37grafana.ini:
38 server:
39 domain: "192.168.68.84"
40 root_url: http://192.168.68.84:30001
41
42adminUser: admin
43
44# Use an existing secret for the admin user.
45admin:
46 existingSecret: "grafana-creds"
47 userKey: admin-user
48 passwordKey: admin-password
Prometheus Operator:
1namespaceOverride: "observability"
2
3defaultRules:
4 create: false
5 rules: {}
6
7global:
8 rbac:
9 create: true
10
11alertmanager:
12 enabled: false
13
14grafana:
15 enabled: false
16
17kubeControllerManager:
18 enabled: false
19
20coreDns:
21 enabled: false
22
23kubeEtcd:
24 enabled: false
25
26
27kubeScheduler:
28 enabled: false
29
30
31kubeProxy:
32 enabled: false
33
34kubeStateMetrics:
35 enabled: true
36
37kube-state-metrics:
38 enabled: true
39 namespaceOverride: "observability"
40 rbac:
41 create: true
42 releaseLabel: true
43 prometheus:
44 monitor:
45 enabled: true
46
47prometheus-node-exporter:
48 namespaceOverride: "observability"
49
50prometheusOperator:
51 enabled: true
52
53 namespaces:
54 releaseNamespace: true
55 additional:
56 - kube-system
57 - home-automation
58 - observability
59 - default
60
61 resources:
62 requests:
63 memory: 400Mi
64 cpu: 400m
65 limits:
66 memory: 600Mi
67 cpu: 600m
68
69 service:
70 nodePort: 30002
71
72 type: NodePort
73
74prometheus:
75 enabled: true
76
77 service:
78 nodePort: 30003
79 type: NodePort
80
81 retention: 2d
82 walCompression: true
83
84 resources:
85 requests:
86 memory: 400Mi
87 cpu: 400m
88 limits:
89 memory: 600Mi
90 cpu: 600m
91
92 storageSpec:
93 volumeClaimTemplate:
94 spec:
95 accessModes: ["ReadWriteOnce"]
96 resources:
97 requests:
98 storage: 50Gi
99
100 additionalScrapeConfigs: []
Black box Exporter:
1kind: Deployment
2
3image:
4 repository: prom/blackbox-exporter
5 tag: v0.19.0
6 pullPolicy: IfNotPresent
7
8config:
9 modules:
10 http_2xx:
11 prober: http
12 timeout: 5s
13 http:
14 valid_http_versions: ["HTTP/1.1", "HTTP/2.0"]
15 follow_redirects: true
16 preferred_ip_protocol: "ip4"
17
18allowIcmp: true
19
20resources:
21 limits:
22 cpu: 150m
23 memory: 300Mi
24 requests:
25 cpu: 100m
26 memory: 50Mi
27
28serviceMonitor:
29 enabled: true
30
31 defaults:
32 labels:
33 release: prometheus-operator
34
35 targets:
36 - name: blog
37 url: https://caffeinatedcoder.dev
38 interval: 300s
39 scrapeTimeout: 5s
40 module: http_2xx
Now, let's unpack all of this, starting with Grafana. First off, we're using a stateful set for persistence. This means that instead of having a separate database for the Grafana state, we're using a Kubernetes persistent volume claim and storing the state on the K8s cluster itself. What this also means is that we need to keep our deployment replica count to 1 replica. This is because with more than 1 replica, requests to Grafana will bounce back and forth between the pods in the stateful set and things like sessions will not behave properly as each pod ends up with its own distinct PVC. Now, this works well enough for a small home lab setup, but for a proper production ready setup, its best to store Grafana state in a proper database (e.g. MySQL) and to bump up the deployment to have more than 1 replica.
We're also using a simple node port service to expose Grafana, which means the application is available on a given port on the K8s node (in our case 30001). But again, in a production setup, its best to have a proper LoadBalancer service or ingress setup with a hostname in front of it. Finally, no matter what method you use to expose Grafana, you'll want to make sure that you match the endpoint in your grafana.ini file by specifying the "root_url" and "domain" attributes.
Now, moving onto the Prometheus Operator. For Prometheus, I've gone with a pretty standard setup. Again, going with the node port service for exposing the Prometheus server outside the cluster, and using a K8s PVC for the metrics data that are stored on disk. I've also opted to disable a few components as I don't need them right now. Now as for basic Prometheus configuration, I've specified a retention of 2 days as I don't need much metrics history for my use case and would prefer to save on disk space. This value can easily be increased, but depending on your scrape interval and how many jobs you have configured, this could start eating up disk space faster than you'd think.
Finally, let's talk about the most important part, the Black box Exporter. This is the piece that ties all of what we have so far together. Now there are 2 main parts of the YAML I want to call out. First off, we specify a basic HTTP module. This module is used by the corresponding Prometheus jobs to determine how the Black box Exporter is used. In our case, we're specifying a 5 second timeout and telling it to follow redirects. The timeout is important as it will also provide insight to your site's performance.
The second thing to call out is the service monitor section of the YAML. Service Monitors are a custom resource type included with the Prometheus Operator. What service monitors do is essentially capture a Prometheus job configuration in a K8s resource. So instead of repeatedly adding to your Prometheus config file, each helm chart or K8s release can include a service monitor that will automatically start getting scraped by Prometheus. Now the target block has my blog's domain name defined and also an interval of 300 seconds. Typically you want to keep your scrape intervals shorter, maybe maxing out at around 2 minutes. But I've opted for a little higher of an interval just to save on bandwidth on my infrastructure. All of this together creates a service monitor with a job that scrapes my blog every 5 minutes and Prometheus picks up on this and starts pulling in those metrics. Its important to note that the service monitor needs to have the matching label fo the Prometheus operator itself. In our case, our Prometheus Operator has the label release=prometheus-operator so we've added the same to our service monitor.
At this point, we have the Black box exporter monitoring our site and the metrics being aggregated in Prometheus. The only thing left to do is visualize it. And as you remember, that's where Grafana comes in.
First step is to create the Prometheus data source in Grafana. For this, we could use the Node Port service, but where both Grafana and Prometheus are on the same K8s cluster, we can use the internal K8s service name. For our use case, this will follow the format <prometheus service name>.<namepsace name>.svc.cluster.local:9090. For the rest of the data source config, we can just keep the defaults.
As for the actual visualizations, the Grafana community is quite good about maintaining standard dashboards for standard metrics libraries, including one for the Prometheus Black box Exporter. So from here, we can select the "Import" button from the "new dashboard" menu in Grafana. On the next screen, you can paste the dashboard ID from the above link. This will import the dashboard JSON onto our Grafana deployment. The last thing we have to do, is just select our Prometheus data source we just created. The finished product once you create the dashboard is below:
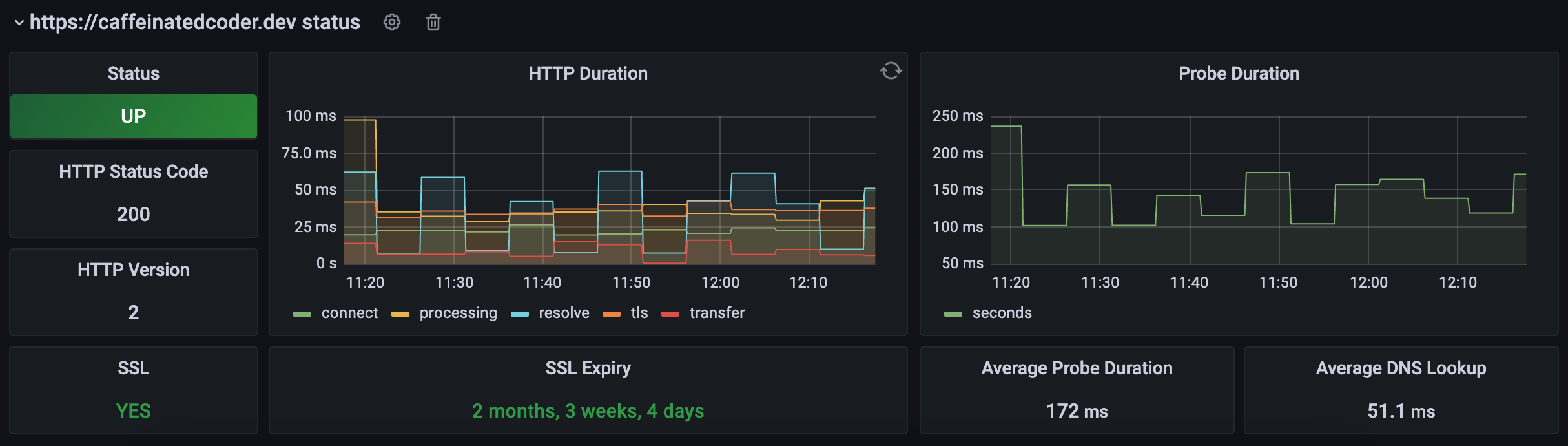
Its also worth noting that the black box exporter doesn't falsely report users on Google Analytics as it doesn't actually execute the JavaScript code included in the response of the website. So even though we're technically visiting the website every 5 minutes, we don't see an artificial influx of users.
So that's about all I have for this post! For a follow up to this post, I'll be discussing more on the CI/CD workflow I have for the Helmfile deployments in this post. So stay tuned!